Quietly intelligent app features with OpenAI Agent Builder
How I used OpenAI’s Agent Builder to power an “invisible AI” feature in Collxn. What I learned about LLM reliability, schema design, and control.

I like to think about "invisible AI" in apps. It's not a great term, but by "invisible AI", I mean the kind that works quietly behind the scenes instead of showing up as a chatbot.
Back at Nylas, I built an OpenAI-powered email triage prototype that categorized your inbox without ever announcing itself as “AI.” It just helped the inbox become higher signal without requiring the user to create a ton of brittle rules. Around the same time, I gave a talk at Austin API Summit 2024 that explores that idea a bit further.
As I continue to build out Collxn, I recently had the opportunity to introduce an artist news module to Collxn Daily Drops. The artist news fetcher is actually powered by an AI agent under the hood. But that's an implementation detail. The AI quietly improves the Daily Drop without distracting the user from the main focus: the music.
Putting an AI integration at this level of an app stack is, I believe, elegant but it comes with plenty of hurdles to overcome.
The Challenge
At this point, we all know that working with LLMs programmatically is a strange mix of science and begging. You ask for something, and it can work magically.
But sometimes the LLM skips a requirement, returns malformed data, or produces nothing at all. When you rely on AI to fill in blanks, you learn quickly how many ways said blanks can stay empty or get filled in with nonsense.
Orchestrating a reliable workflow means balancing quality against speed, building fallback paths that make sense, and writing code that can survive bad responses. Every piece of resilience adds friction to the build, but without it, the system eventually breaks in ways that are hard to predict.
To be clear, sane fallbacks and resilience are important for your code regardless of whether you have an LLM in the mix. But when you are calling models, you don't get to fool yourself into thinking an API contract means you're safe.
Using OpenAI Agent Builder
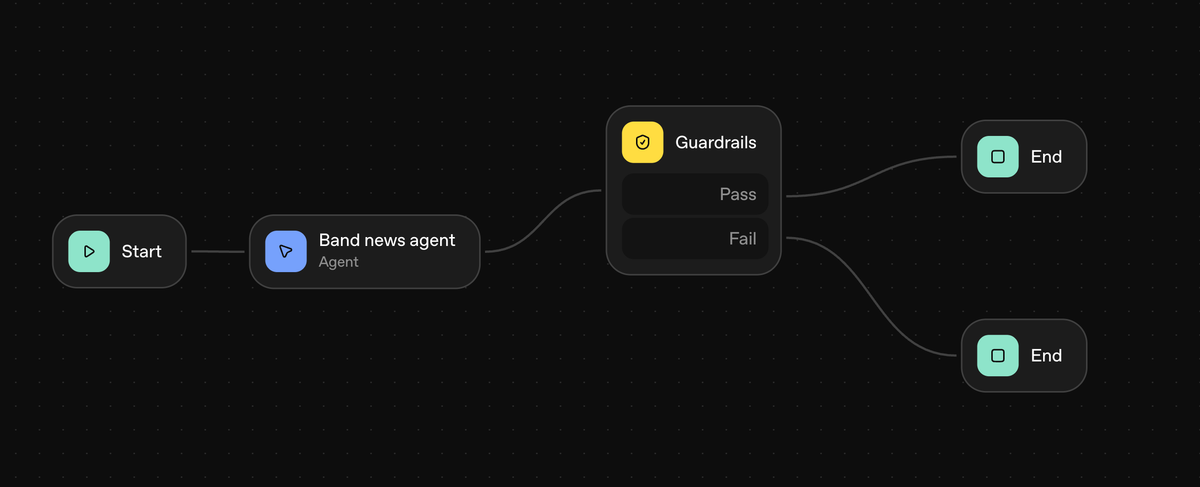
For the Collxn Daily Drop artist news module, I wanted to see if OpenAI’s new Agent Builder could make the process simpler.
Setup was straightforward: attach an agent node, a guardrails node, and then end nodes for pass and fail.
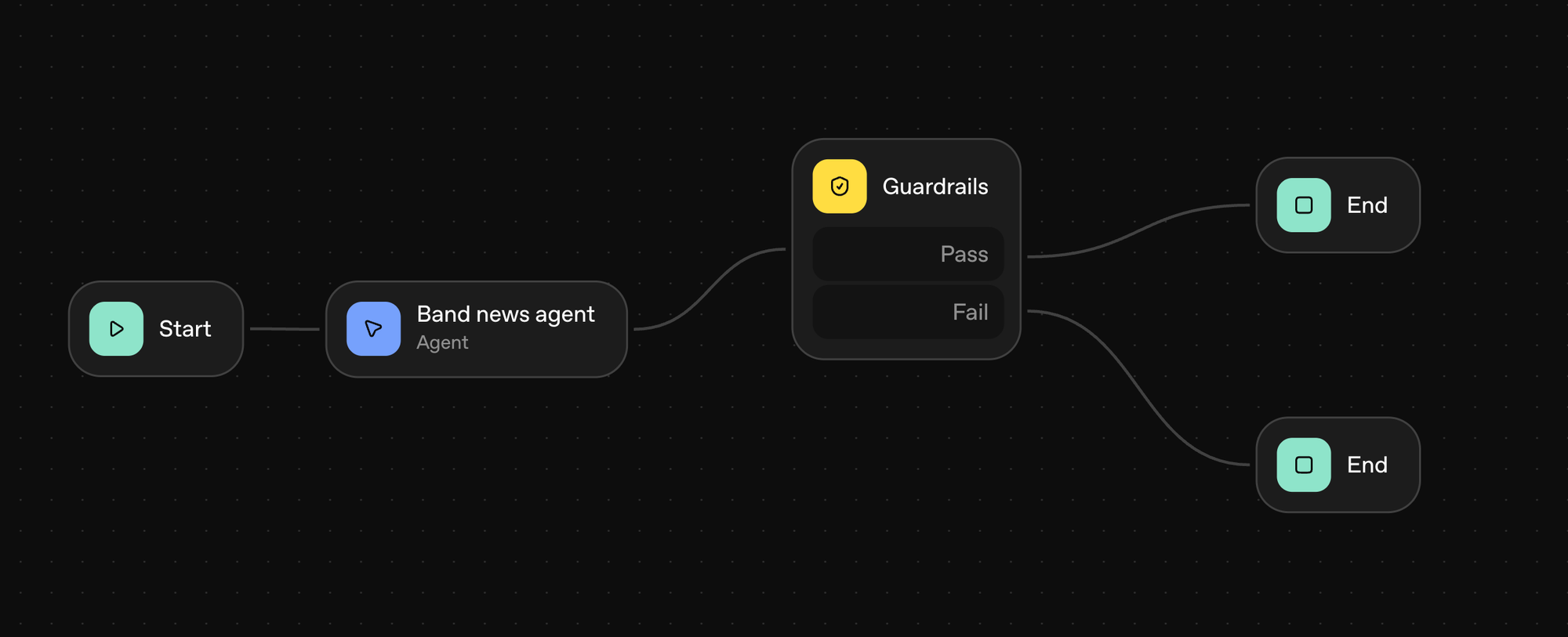
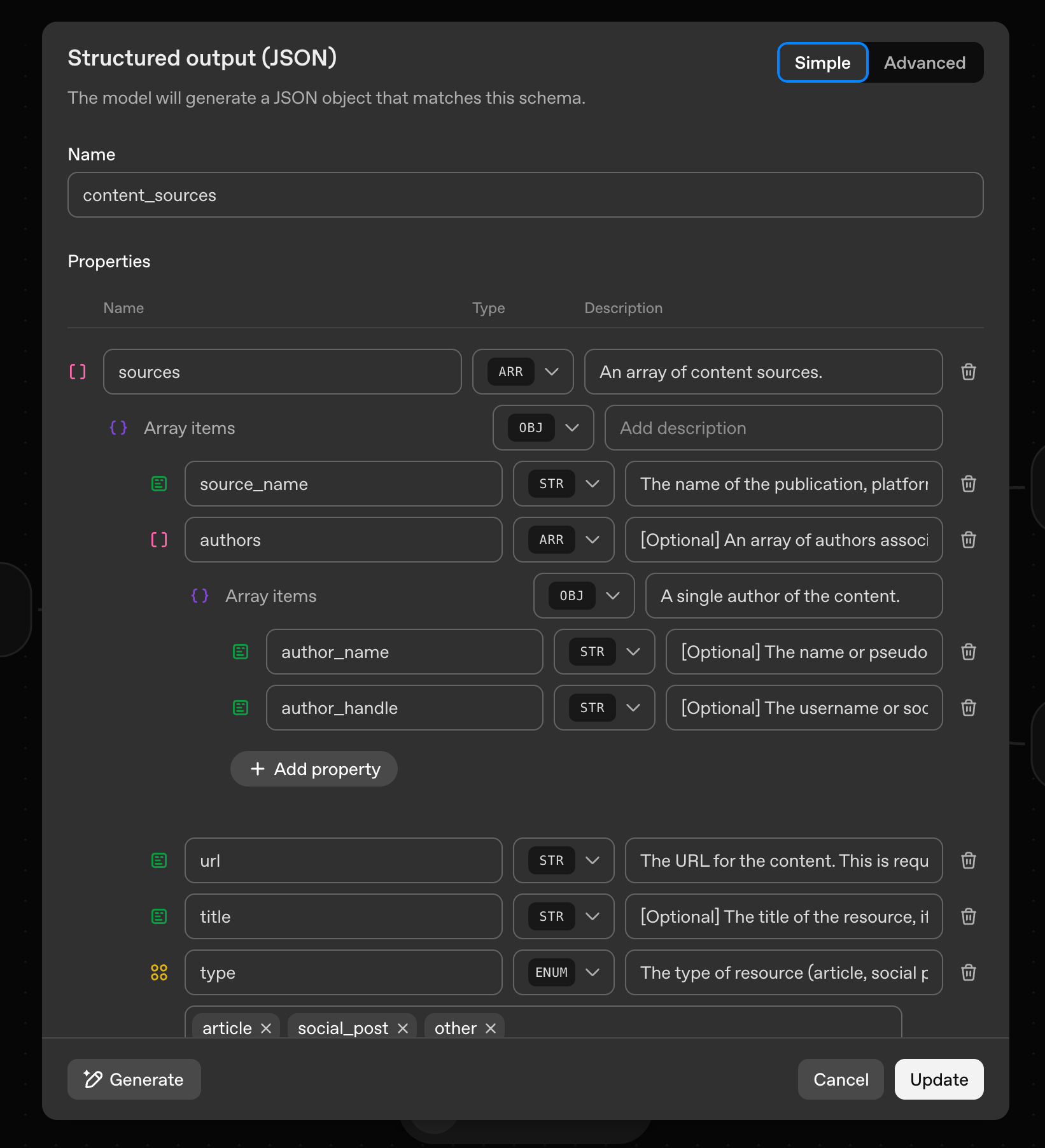
From there I spent time doing trial-and-error in the agent node as I worked to set a prompt, define a JSON schema, and try various models to see which felt like a balance of quality, speed, and cost.
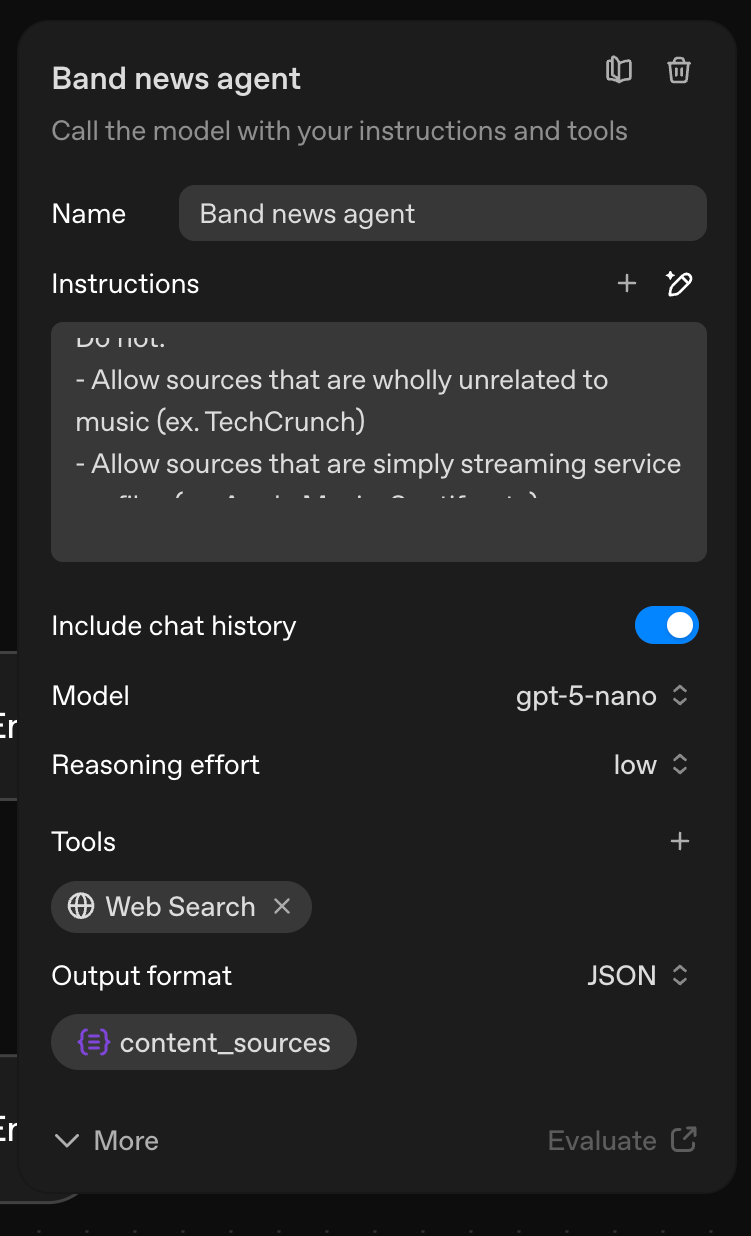
My agent’s task was to search for recent news about the artist featured in each user’s Daily Drop. On paper, that seems pretty simple. In practice, a few rough edges showed up quickly.
- Relevance. Many artist names overlap with unrelated entities (TIL that "Finom", in addition to being an indie rock band from Chicago, is also a fintech co in Europe...). I need the agent to verify that results are actually about the band or musician.
- Short-circuits. Sometimes my app won't have enough info to make a sane prompt. Is the artist name "Various Artists" or "Unknown"? That's not going to make sense for the agent to work on. I need the agent to be bypassed altogether.
- Language. Some artists are better covered in Japanese, others in English. One of my beta users reported getting news about a Brazilian artist in Portuguese; which would be fine, but the user is from the UK. The agent should respect the user's language preferences.
- Data retrieval. The Agent Builder can find pages, but getting reliable snippets or summaries requires additional validation. For example, I want to show a smart preview including a publish date. But many websites don't expose dates at all. The agent should deal with this scenario gracefully.
- Schema management. The UI in Agent Builder for defining and testing schemas is early. I find that as my schema grows, my resistance to this UI grows. I've also started to realize that marking schema fields as "required" or "optional" doesn't really matter much.
- 404s. Even when everything looks fine, some returned links are dead, either due to having been taken down by the author or having been generated through plain old LLM hallucination. While I'd love to force the agent to ping the URL for signs of life first, so far it doesn't seem I can rely on that.
OpenAI Agent Builder in its current beta form is great for prototypes. I did get up and running in basically no time.
But it's at this point in any no-code tool (AppleScript, Apple Automator, and Apple Shortcuts come to mind) that I start asking myself: should I not be coding this instead?
Ejecting into code
Luckily, unlike many other no code products out there, OpenAI Agent Builder gives you the underlying code for your agent.
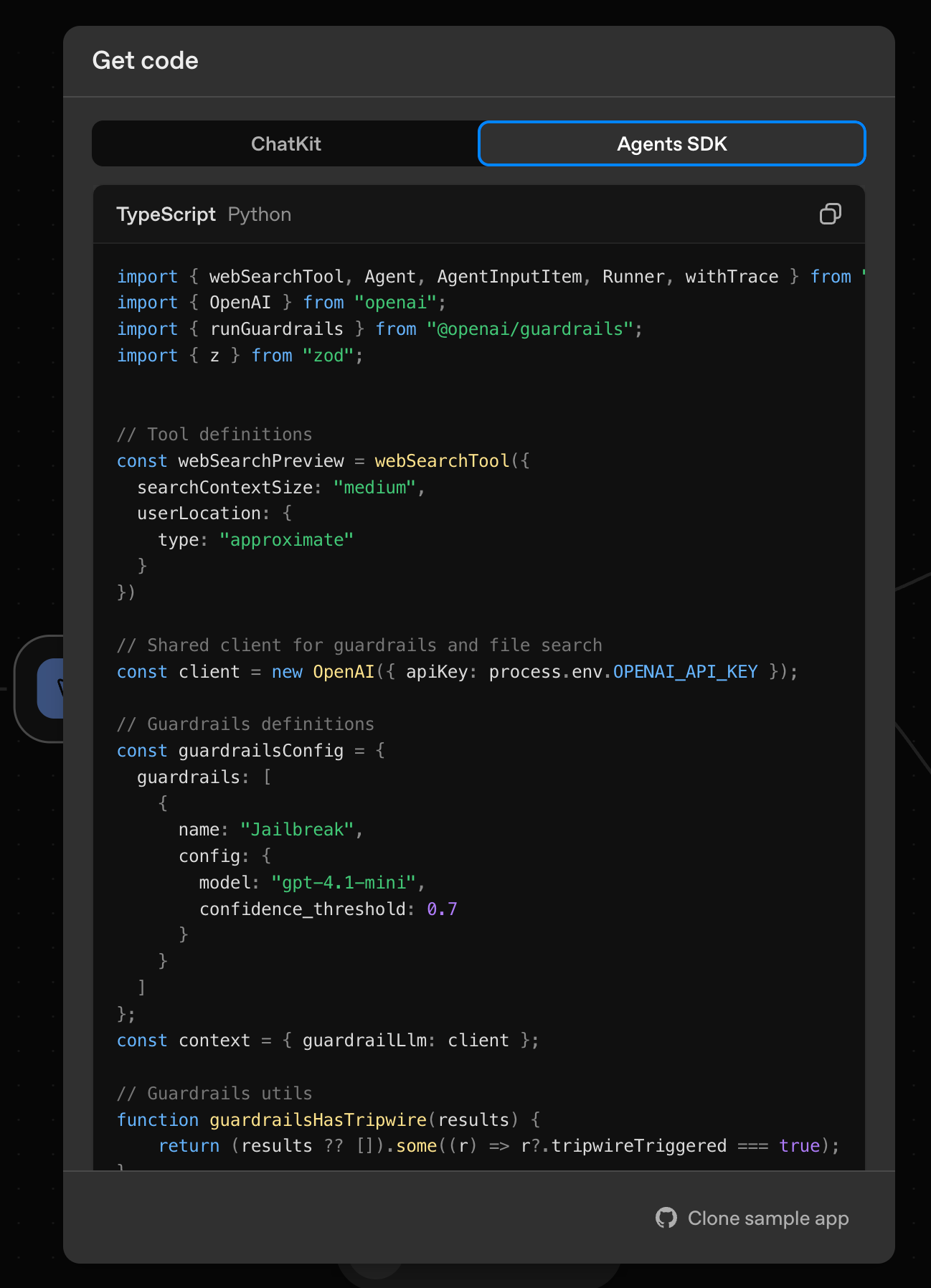
I took this code as a starting point in creating an agent module in my own TypeScript codebase.
The caveat here of course is that my prototype in Agent Builder becomes a stale artifact. As my code evolves, that no-code agent doesn't stay in sync.
This is as expected, but it has implications on the timing of your ejection. Make sure the rapid-prototype-and-iterate phase of your agent's core functionality is done first.
Thoughts and Questions
You can see a live Daily Drop on my Collxn page. This one's from November 3. It's pretty good except it still suffers occasionally from the agent surfacing a URL that 404s.
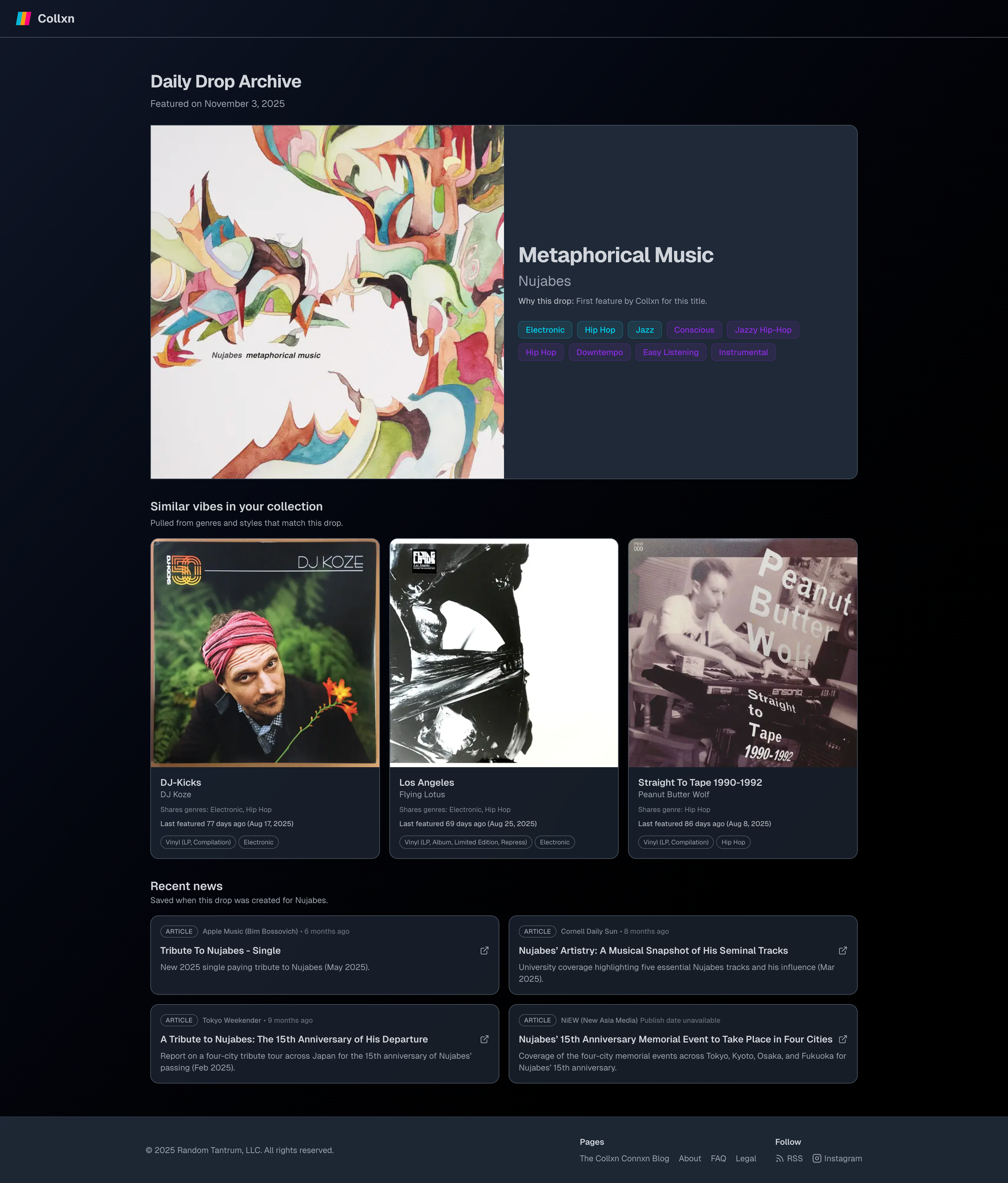
Look at the Tokyo Weekender link on the bottom left.
- The link my agent provided:
https://www.tokyoweekender.com/event/a-tribute-to-nujabes-15th-anniversary-of-his-departure/
- The actual live link:
https://www.tokyoweekender.com/event/a-tribute-to-nujabes-15th-anniversary/
I have a hunch that the incorrect URL isn't an LLM hallucination, but rather cached data. It seems likely that the publisher changed the URL slug after publishing. But this is just a guess on my part.
Ultimately, I'm happy to have Agent Builder as a tool in my belt. It's been a nice place to prototype, test, and interact on the core agent without building dev and debug features into my own codebase just to try something out.
I fully expect that Agent Builder will have more node types and dev tools added to it as it approaches GA.
As I iterate, a few questions come to mind:
- Is it better to request multiple results from the agent and filter later, or to go one-by-one for better precision?
- How much orchestration logic belongs inside the agent, and how much should stay in the app?
- Can schema-based prompts ever guarantee predictable structure from a model that’s inherently probabilistic?
Overall, if you build "invisible AI" deeply into your application features, it becomes more and more clear why chatbots are default for so many LLM use cases. Printing sanitized strings to the screen is well-trodden territory. Wrangling LLM chaos in app logic, on the other hand, is quite an exercise in checking your assumptions at every level of the stack.



